Täglich bieten wir KOSTENLOSE lizenzierte Software an, die ihr sonst bezahlen müsstet!
iPhone Giveaway of the Day - Japanese Sound of Kana Letter
This giveaway offer has been expired. Japanese Sound of Kana Letter is now available on the regular basis.
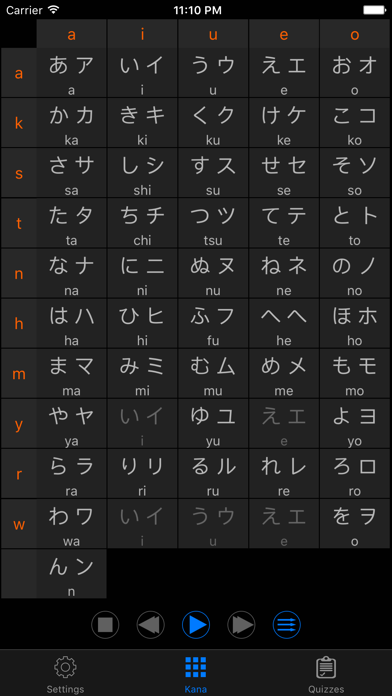
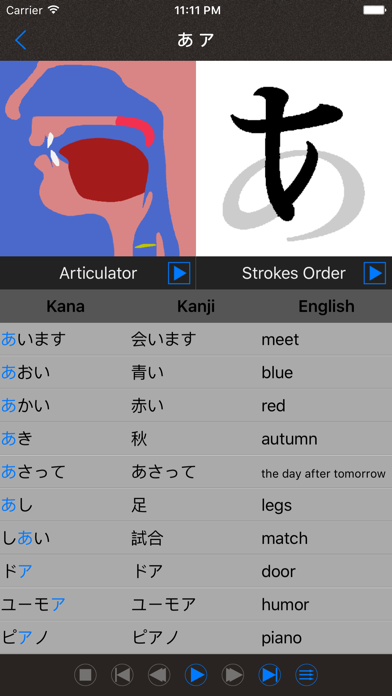
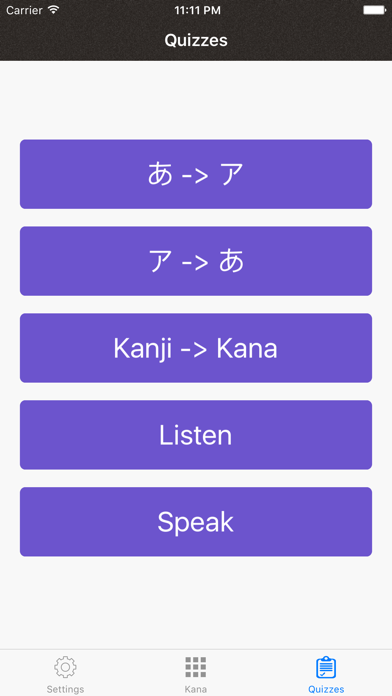
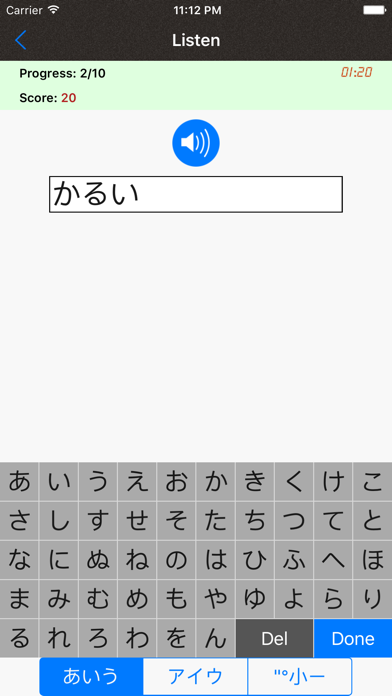
JapSounds can help you learning and mastering the pronunciation of Japanese kana syllabary.
Key features as follows:
1. Include the standard phonetic symbols of Japanese: Seion, Dakuon and Youon.
2. Provide a comprehensive understanding of how every voice is pronounced with the animation of articulator and two kinds of high quality audios including male voice and female voice.
3. Show the order of strokes of symbols with the animation.
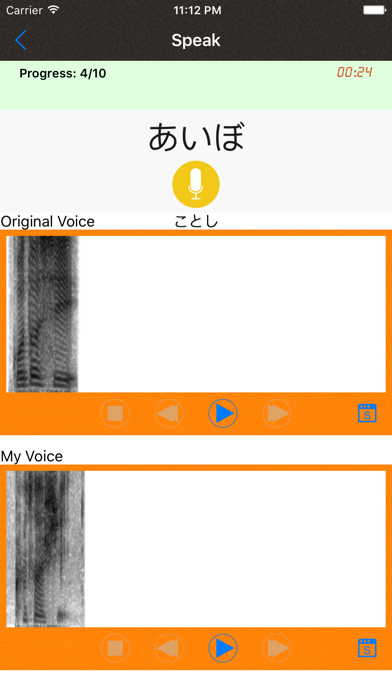
4. Test comprehensively your pronunciation skills by listening and speaking with over 500 words.
5. Help you find the essential features of pronunciation by comparing yours with standard one with VOICEPRINTS.
6. Learn and play the application anywhere without network.
Entwickler:
Wu Peipei
Kategorie:
Education
Version:
17.11.18
Größe:
45.28 MB
Bewertet:
4+
Sprachen:
English, Japanese, Chinese, Chinese
Kompatibilität:
iPhone, iPad, iPod touch

Kommentare zum Japanese Sound of Kana Letter