Täglich bieten wir KOSTENLOSE lizenzierte Software an, die ihr sonst bezahlen müsstet!
iPhone Giveaway of the Day - My Books Read
My Books Read
ist verfügbar als Giveaway of the day!
Ihr habt nur begrenzt Zeit, es herunterzuladen und zu installieren.



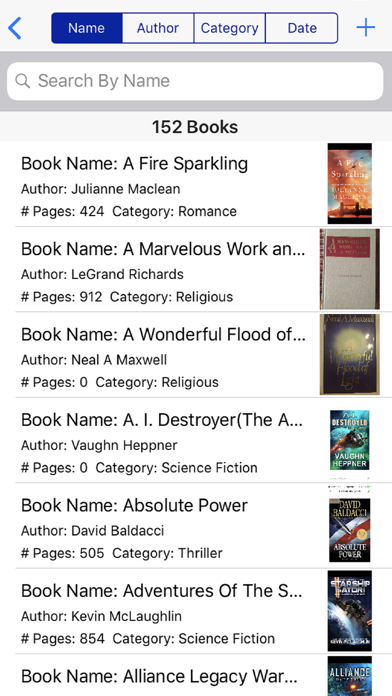
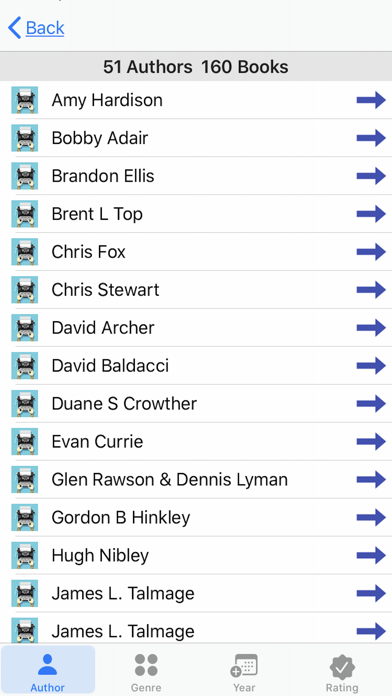

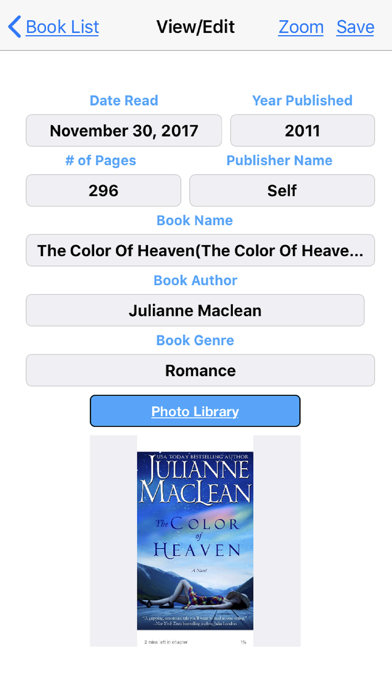

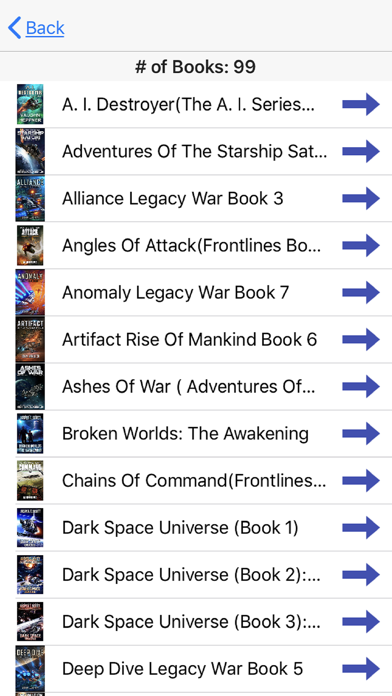
You can keep track of all the books you have read.
When is the last time someone ask you for advice on a good book to read? With this app you can simply find the book and go to details and top the share button and share with your friend or relative all the pertinent information about the book by means of a text, email, Facebook, Twitter, Snapchat or what ever sharing app you have on your iPhone or iPad.
You see a book advertised by a Author you like and it is one out of 15 in a series and you can't remember if you have read it or not. You can simply open the app and use the menu option Book List by Author / Genre select the Author tab on the bottom and scroll down to find you author and tap to get a list of books by that author and see if it is one you have read or not.
You can sort by Book Name, Author, Genre and Date Read as well as grouping books by author and genre.
Entwickler:
Bryan Hall
Kategorie:
Book
Version:
1.26
Größe:
7.05 MB
Bewertet:
4+
Sprachen:
English
Kompatibilität:
iPhone, iPad

Kommentare zum My Books Read